Attention is All You Need: The Paper that Changed AI
Attention is All You Need
Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar et al.
Publication Date: June 2017
Published In: NeurIPS 2017
Number of Citations: 80,000+
Link to Paper: arXiv.org/attention
Table of Contents
- Brief Description
- Main Topic
- Key Concepts
- Methodology and Experiments
- Results and Practical Impact
- Limitations
- References and Related Work
- Conclusion and Takeaways
- Thanks for Reading
Brief Description
This seminal paper introduced the Transformer architecture, which relies entirely on attention mechanisms, revolutionizing natural language processing and laying the foundation for modern generative AI. The architecture has become the backbone of models like GPT, BERT, and their successors.
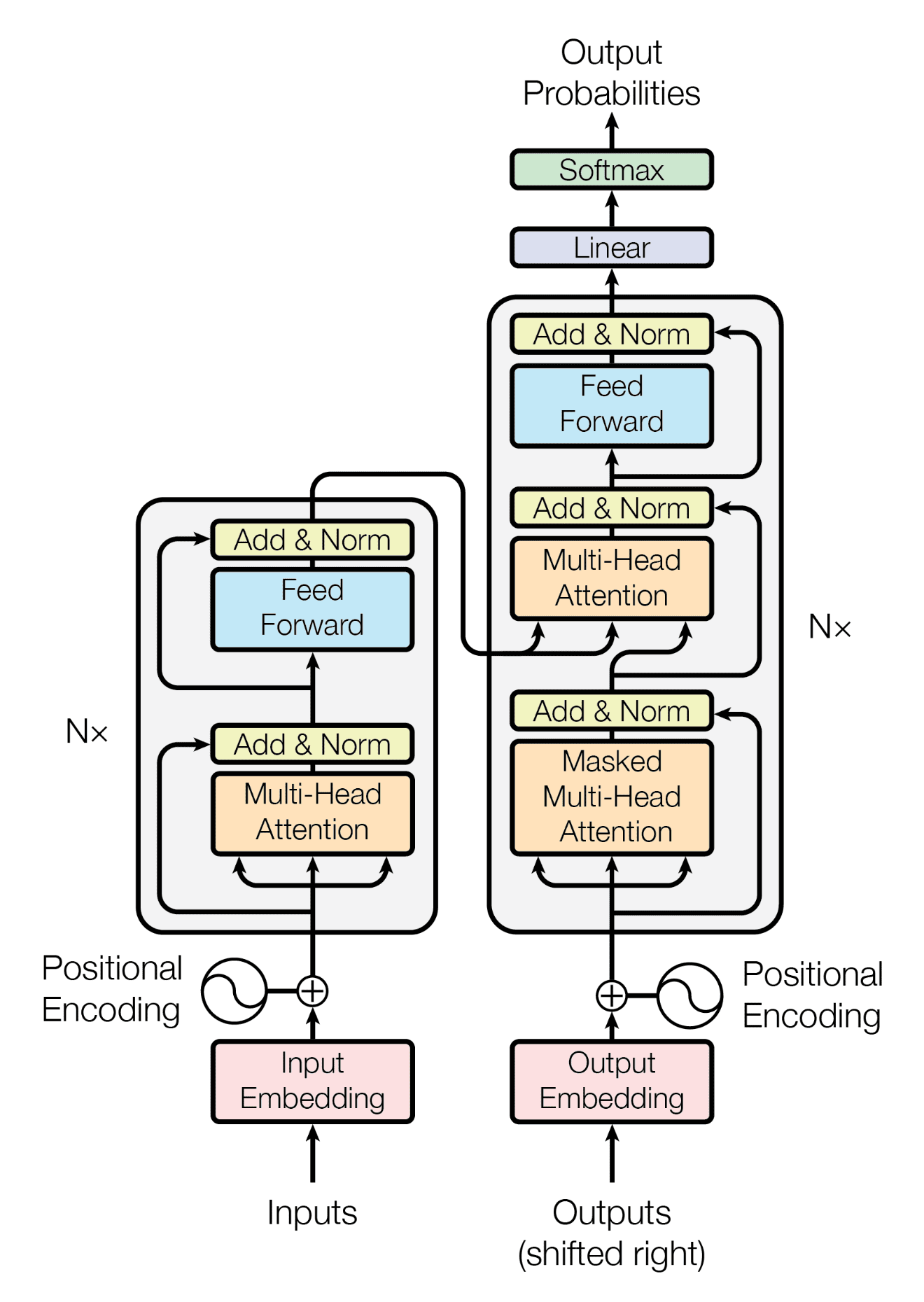
Main Topic
The paper introduces the Transformer, a groundbreaking neural network architecture designed for sequence-to-sequence tasks (e.g., translation, language modeling), which exclusively utilizes self-attention mechanisms and eliminates recurrent and convolutional layers.
Contextualization (Relevance at Publication Time): Prior to this paper, the dominant approaches in NLP tasks relied heavily on Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). However, RNNs suffered from challenges such as vanishing gradients and slow sequential computations, which limited their parallelization capabilities and performance on long sequences.
The introduction of the Transformer was timely and highly impactful, addressing these challenges by enabling more efficient parallel computations and better long-range dependency modeling, fundamentally shifting NLP model design and rapidly becoming the backbone for state-of-the-art NLP architectures like BERT and GPT.
Key Concepts
1. Self-Attention Mechanism
- • Allows each position in the sequence to simultaneously attend to all other positions.
- • Computes attention weights based on the relationships between queries, keys and values.
- • Facilitates efficient parallel processing of input sequences, significantly reducing computational time compared to RNNs.
- • Captures dependencies irrespective of their distance within the sequence (both short-term and long-term relationships).
2. Multi-Head Attention
- • Divides the self-attention mechanism into multiple parallel “heads,” each with its own learned linear projection of queries, keys, and values.
- • Each attention head can independently attend to different aspects of the input data, capturing distinct relationships and patterns.
- • Outputs from multiple heads are concatenated and projected back into a unified representation, enhancing the model’s ability to process complex contexts.
- • Crucially enhances the model’s capacity to simultaneously represent different types of semantic or syntactic relationships.
3. Position-wise Feed-Forward Networks
- • Consists of two linear transformations separated by a ReLU activation, applied identically but separately at each position.
- • Adds significant computational capacity beyond self-attention, improving the model’s representational power.
- • Provides depth to the model without involving recurrence, thus maintaining computational efficiency.
4. Positional Encoding
- • Incorporates explicit positional information into input embeddings to help the model understand sequence order.
- • Employs sinusoidal functions (sine and cosine) of varying frequencies for each embedding dimension.
- • Ensures the Transformer can handle sequences of varying lengths and generalize effectively to sequence lengths not encountered during training.
- • Critical for Transformers since the architecture itself does not inherently encode positional information.
Methodology and Experiments
The authors conducted extensive experiments to evaluate the effectiveness of the Transformer model compared to previous state-of-the-art sequence to sequence architectures. Specifically, they focused on machine translation tasks, which serve as standard benchmarks for assessing model performance and generalization capabilities.
- Translation Tasks:
-
• WMT 2014 English-to-German Translation:
- ◦ Dataset: ~4.5 million sentence pairs.
- ◦ Vocabulary: Byte-pair encoding (~37k tokens shared between source and target).
-
• WMT 2014 English-to-French Translation:
- ◦ Dataset: ~36 million sentence pairs (significantly larger dataset).
- ◦ Vocabulary: Word-piece encoding (~32k tokens).
- Model Configurations:
- • Base model:
- ◦ Approximately 65 million parameters.
- ◦ 6-layer encoder and decoder stacks.
- ◦ Model dimension: 512, Feed-forward inner-layer dimension: 2048.
- ◦ 8 attention heads per layer.
- • Big Model:
- ◦ Approximately 213 million parameters.
- ◦ 6-layer encoder and decoder stacks.
- ◦ Model dimension: 1024, Feed-forward inner-layer dimension: 4096.
- ◦ 16 attention heads per layer.
- ◦ Higher dropout rate (0.3) specifically tuned for larger capacity.
- Training Details:
- • Optimizer: Adam with a customized learning rate schedule that increases linearly during a warm-up period and then decays proportionally to the inverse square root of the step number.
- • Regularization:
- ◦ Dropout applied to sub-layer outputs, embeddings, and positional encodings to prevent overfitting.
- ◦ Label smoothing (value = 0.1) was employed to enhance model generalization and improve BLEU scores, despite slightly increasing perplexity.
- • Decoding:
- • Beam search algorithm with a beam size of 4 was used for generating translations, coupled with a length penalty hyperparameter (α=0.6) to optimize sentence length.
These meticulous experimental setups allowed the authors to clearly demonstrate that the Transformer not only outperforms previous recurrent and convolutional neural network architectures but also achieves state-of-the-art results with significantly reduced training time.
Results and Practical Impact
Performance Achievements
State-of-the-Art Translation Performance: set new state-of-the-art BLEU scores on WMT 2014 translation tasks:
- • English-to-German: Achieved BLEU score of 28.4, surpassing previous models by over 2 points.
- • English-to-French: Achieved BLEU score of 41.8, significantly outperforming previous benchmarks.
Efficiency and Scalability:
- • Dramatically reduced training times compared to RNN and CNN-based models (e.g., trained within ~3.5 days versus weeks).
- • Demonstrated significantly higher parallelization capabilities, making effective use of GPU clusters.
- • Required substantially fewer computational resources, thereby making powerful NLP models accessible to broader research communities and industry.
Industry Impact
- Architecture Adoption: The Transformer rapidly became the foundational architecture for many revolutionary NLP models, including:
- • BERT (Bidirectional Encoder Representations from Transformers)
- • GPT series (Generative Pretrained Transformers), notably GPT-3, GPT-4
- • Numerous other variants and derivatives like RoBERTa, T5, and XLNet.
Enabled groundbreaking achievements across diverse NLP tasks such as language modeling, text classification, and conversational AI. Inspired new architectures beyond NLP fields, influencing vision transformers (ViT), audio transformers, and multimodal transformers.
- Practical Applications:
- • Machine Translation Systems: Enabled rapid advancement in translation services (e.g., Google Translate, DeepL).
- • Text Generation Models: Basis for high-quality text generation systems used in content creation, storytelling, and conversational AI.
- • Document Summarization: Improved accuracy and coherence in automated summarization systems.
- • Code Completion Tools: Enabled sophisticated code generation tools like GitHub Copilot.
- • Multimodal AI Systems: Facilitated the integration of different data modalities (text, images, audio) within unified Transformer-based models.
The Transformer architecture’s practical impact is vast and continues to shape the trajectory of modern AI developments across numerous applications and industries.
Limitations
Technical Limitations
- Strengths:
- • Simplified and Effective Architecture: The Transformer architecture simplified neural network design by removing recurrent and convolutional components, making models easier to scale, parallelize, and optimize.
- • Enhanced Contextual Understanding: Self-attention allows effective handling of both short and long-range dependencies, significantly improving model performance in sequence tasks.
- • Highly Influential: Set a new direction for NLP research and was rapidly adopted across multiple AI domains, reflecting its significant impact.
- Weaknesses and General Limitations:
- • Computational Complexity of Self-Attention: Standard self-attention has quadratic complexity with respect to sequence length, leading to practical limitations when dealing with extremely long sequences (e.g., documents, books).
- • Lack of Intrinsic Positional Awareness: Requires explicit positional encodings, which are essential but somewhat limited in their representational capacity for very long sequences or sequences that significantly exceed lengths seen during training.
- • Resource Intensive at Scale: While it greatly improved efficiency compared to RNNs and CNNs, training very large Transformer models (e.g., GPT-3, GPT-4) remains resource-intensive, requiring substantial computational infrastructure.
- Identified Gaps and Subsequent Improvements:
- • The quadratic computational complexity has prompted research into variants like the Longformer and Reformer, employing sparse attention and more efficient attention computations to handle longer sequences.
- • Positional encoding limitations have inspired further innovations, such as learned positional embeddings and relative position encoding methods.
- • Continued research on efficiency and scalability has led to ongoing developments in model compression, sparsity techniques, and quantization.
Although highly influential, the original Transformer architecture laid the groundwork for numerous improvements and variations, demonstrating both its significance and the areas where future advancements were needed.
References and Related Work
Core References (cited by authors):
- • Sequence to Sequence Learning with Neural Networks (Sutskever et al., 2014) Introduced encoder-decoder architectures based on RNNs.
- • Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2015) Proposed attention mechanisms in neural machine translation, foundational for self-attention development.
- • Convolutional Sequence to Sequence Learning (Gehring et al., 2017) Presented CNN-based approaches for sequence tasks, competing method at publication time.
Subsequent Influential Work (inspired by this paper):
- • BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018) - Bidirectional Transformer-based pretraining, revolutionizing NLP benchmarks.
- • Improving Language Understanding by Generative Pre-Training (Radford et al., 2018) and Language Models are Few-Shot Learners (Brown et al., 2020) - Generative Pretrained Transformers, advancing language modeling and text generation.
- • RoBERTa: A Robustly Optimized BERT Pretraining Approach (Liu et al., 2019) - Improved pretraining methods inspired by BERT and Transformer architecture.
- • Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019) - Unified Transformer architecture for multiple NLP tasks via text-to-text paradigm.
- • An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al., 2020) - Extended Transformer concepts to computer vision tasks, achieving strong results compared to CNN-based models.
- • Robust Speech Recognition via Large-Scale Weak Supervision (Radford et al., 2022) - Applied Transformer architecture effectively to audio recognition and transcription.
Conclusion and Takeaways
The Transformer model introduced by Attention is All You Need marks a fundamental turning point in artificial intelligence, especially within Natural Language Processing. By relying entirely on attention mechanisms and removing recurrence and convolutions, the paper unlocked unprecedented levels of parallelization, scalability, and performance in sequence modeling.
Key Takeaways:
- • Self-attention is not just an architectural trick — it redefines how models understand context across sequences.
- • Multi-head attention and position-wise feed-forward layers provide flexibility and depth to the model, enabling rich, composable representations.
- • Positional encodings, though a workaround, are critical in enabling order sensitivity in an otherwise position-agnostic model.
- • The training regime (Adam optimizer with warm-up, label smoothing, dropout) is just as important as the architecture itself for stable, high-performing results.
Why This Paper Still Matters:
- • It forms the core foundation of almost every modern large language model, from BERT and GPT to PaLM and Claude.
- • Its architecture has influenced AI research beyond NLP, including vision (ViT), speech (Whisper), and even multi-modal models.
- • Understanding this paper is essential knowledge for AI engineers, ML researchers, and NLP practitioners today.
Thanks for Reading
If you’ve made it this far, thank you for your time and attention. I hope this space becomes useful to you — as a reference, inspiration, or a push to go further. The AI engineering journey is intense, full of uncertainty, but also full of amazing discoveries. That’s why it’s worth sharing.
If you want to exchange ideas, collaborate, or just follow my work, find me on LinkedIn or check out my repositories on GitHub.
Let’s enhance the future of AI together.